This article walks you through the basics of streams in Snowflake. We start with what they are for and move into more complex concepts such as their architecture and how they work.
We’ll also dive into what you need to know to get started:
- creating streams
- querying streams
- handling staleness
- dealing with performance considerations
Let’s get into it.
Table of Contents
Role Of Streams In Snowflake
Streams are Snowflake’s implementation of Change Data Capture (CDC) that is found in other database systems like Microsoft SQL Server.
Streams allow you to track and manage data changes in tables. When you create a stream on a table, Snowflake keeps a continuous record of these changes that you can query.

What Are Streams?
Streams in Snowflake are objects that record Data Manipulation Language (DML) changes (INSERT, UPDATE, and DELETE operations) in a table from a specific point in time.
A stream allows you to view and analyze the data changes in a table since the stream was initiated or since the last time changes were consumed from the stream. The power comes from providing this tracking in real time.
It’s important to understand that a stream is not a physical storage of data. It contains metadata about the changes made to the data in the table on which it’s created.
Streams maintain their state independently of all other streams and consumers. This allows multiple use cases to consume the change data independently and according to their individual timelines.
How Streams Work
Take an example of a row in a product table that looks like this:
| ID | Name | Category |
| 4 | Pen | Office Supplies |
You run an update that changes the category in this row. What happens if a stream had been created on the table before you run the update?
Here’s a simplified step-by-step of what happens.
- When a stream is created on a table, it starts recording changes.
- The update is captured by the stream along with information about the transaction that caused it.
- Users can query the stream just like any other table.
This infographic shows the process. The update statement is on the left, with a representation of how the row changes.
The stream is on the right. It is literally a table with information about the before-and-after state of the row.
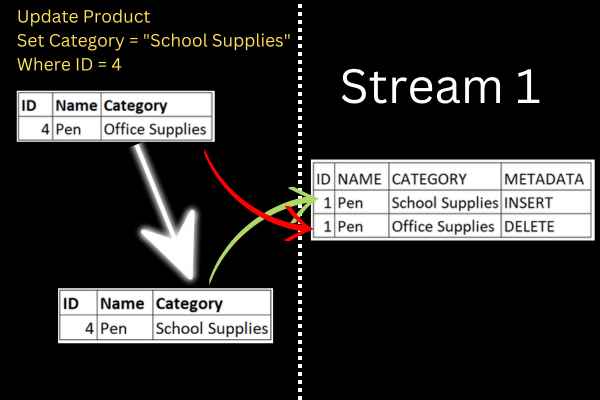
When a user queries the stream and commits the transaction, the changes consumed by that query are cleared from the stream. This means that each change is available to be consumed once from the stream.
The stream continues to track and present new changes to the underlying table, allowing for continuous data analysis.
How Can Multiple Use Cases Query The Same Changes?
You may be wondering how several use cases can query the same changes. After all, once changes are consumed from a stream in Snowflake, they are cleared from that stream.
The key is that each use case creates a separate stream on the same table. Each stream tracks and stores the changes to that table independently.
This way, each use case can consume the changes at its own pace without affecting the others.
How Streams Are Stored in Snowflake
To understand how streams are stored in Snowflake, you first need to learn about stream metadata.
Rather than storing the actual data, a stream records metadata that allows users to query and understand the changes made to the underlying data.
- Updated row: a stream stores both the pre-update and post-update versions of the row.
- Deleted row: a stream stores the state of the row before deletion.
- Inserted row: a stream stores the state of the row after insertion.
Storing metadata makes this a very lightweight mechanism. And because the metadata is stored in relational format, it can be queried like any other table in Snowflake.
Streams Don’t Store Extra Data To Track Updates – But Snowflake Does?

It may seem contradictory to say that streams don’t store data, but they can access the pre and post-versions of an updated row. Isn’t that just pretending that streams don’t include the extra data?
Well, no.
It’s true that when a row in a Snowflake table is updated, the old version of the row and the new version of the row are both stored physically.
But this is part of Snowflake’s underlying data storage and versioning mechanism, not the stream itself. It happens whether there is a stream on the table are not.
Snowflake’s architecture is based on immutable storage. When a row is updated, Snowflake writes a new version of the row while retaining the old version. This enables features like Time Travel and Fail-safe.
Streams are an optional extra that take advantage of this immutable storage. They basically provide pointers (in terms of metadata) to the old and new versions.
What Storage Costs Are Associated With Streams?
I mentioned earlier that streams aren’t physical objects, so how can they produce storage costs?
Because a stream references a historical version of the base table’s data, Snowflake must maintain the data in its historical state until all the changes have been consumed by the stream and the transaction is committed.
In other words, the pre-change row of our sample data is stored in a micro-partition. When the data is updated on a table that has a stream, that row is kept in storage. The updated row is stored separately.
The longer that changes are left unconsumed in a stream, the more historical data Snowflake must maintain in its storage layer. Over a prolonged period, you will see extra costs.
How To Create A Stream On A Snowflake Table
You need to have the necessary privileges on:
- the schema where you want to create the stream.
- The schema with the table.
Yes, the stream can be in a separate schema.
The CREATE STREAM statement creates a new stream. This is the basic syntax:
CREATE STREAM [stream name] ON TABLE [table name];There are lots of additional parameters and options but this will get you started.
Snowflake Create Stream Example
You can follow along with this worked example.
This code creates a table and inserts three records:
Create Or Replace Table PRODUCT (
Id VARCHAR NOT NULL PRIMARY KEY,
NAME VARCHAR NOT NULL,
CATEGORY VARCHAR
);
INSERT INTO PRODUCT VALUES (1, 'Pen', 'Office Supplies');
INSERT INTO PRODUCT VALUES (2, 'Pencil', 'School Supplies');
INSERT INTO PRODUCT VALUES (3, 'Crayon', 'School Supplies');If you want some extra background on these statements, we have an article on how to create tables in Snowflake.
Now that we have a table, we can create a stream on it:
CREATE STREAM product_stream ON TABLE product;Types Of Streams
There are three types of streams in Snowflake:
- Standard Streams
- Append-Only Streams
- Insert-Only Streams
The standard stream is created with the syntax in the previous section and tracks inserts, updates, and delete statements.
Append-Only Streams
An append-only stream only tracks insert operations. This improves performance if it matches your requirements. This is the syntax:
CREATE STREAM [stream name] ON TABLE [table name] APPEND_ONLY = TRUE;Insert-Only Streams
This is the same concept as the append-only tables but it is only for external tables. This is the syntax:
CREATE STREAM [stream name] ON EXTERNAL TABLE [table name] INSERT_ONLY = TRUE;How To Query A Stream In Snowflake
The beauty of streams is that you query them just like any other table. In other words, you use the SELECT statement.
Let’s run through an example.
Step 1: Create a stream on the product table.
CREATE STREAM product_stream ON TABLE product;Step 2: Run an update on the product table.
UPDATE product SET category = ‘School Supplies’ WHERE ID = 1;Step 3: Query the stream.
SELECT * FROM product_stream;You will see two rows for a single update statement.
Each row in a stream has additional metadata columns that provide information about the change.
For example, when the METADATA$ACTION column shows ‘INSERT’, it is the new version of the row after an update. If it shows ‘DELETE’, it is the old version of the row before the update.
Here is the result from our example:
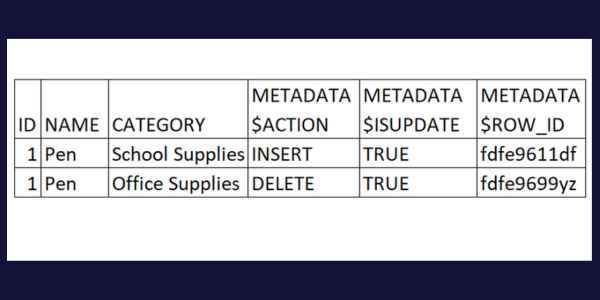
You can run this SELECT statement repeatedly. The change is retained until you clear the stream.
Step 4: Commit the consumed changes in the stream.
After querying the changes, you typically process them in some way. This could involve transforming the data, loading it into another table, analyzing it, etc. The specifics will depend on your use case.
Once you have queried and processed the changes, you commit the transaction. You do this using the COMMIT command:
COMMIT;What Is A Stream Offset?
An offset refers to the position of a specific piece of data within a stream. It’s a way to keep track of where you are in a stream when reading data from it.
When you create a stream, it takes a snapshot of the current data at that point in time. When any data change occurs in the base table, the offset moves forward.
Can You Create Streams On Views?
So far, we’ve looked at creating streams on tables. But what about views?
When Snowflake first launched, you couldn’t create a stream on a view. Snowflake has since introduced the ability as a new feature…with some limitations. Here are the main three:
- You can create streams on standard and secure views, but not on materialized views.
- The view can only be on native tables.
- Some more unusual types of joins aren’t allowed.
What Happens When A Snowflake Stream Goes Stale
The term “stale” refers to the state of a stream when it’s no longer able to capture and reflect changes from its source table.
This obviously happens when the stream’s source table has been dropped. However, there is a more common reason for the stream to go stale.
Snowflake tables have a data retention period that defines the duration that Snowflake keeps its historical data. The default is 24 hours.
If the stream offset gets older than the data retention period, the stream becomes stale. This applies to a single table, or any table within a view.
When a stream becomes stale, it can’t track new changes to the table. If you still need to track changes, you would need to create a new stream on that table.
The best solution is to consume the stream within the data retention period. This ensures that the feature functions as it’s supposed to.
How To Check If A Stream Has Data
You can run the SELECT statements that we’ve shown already.
However, there is a built-in function, SYSTEM$STREAM_HAS_DATA, that provides a faster way to check if there are uncommitted transactions in the table.
The function returns TRUE or FALSE depending on whether there is unconsumed data.
Here is an example of using it with our sample table:
SELECT SYSTEM$STREAM_HAS_DATA('product_stream');Performance Considerations

Streams can help improve the performance of ETL operations by identifying and processing only the data that has changed, rather than reprocessing the entire table.
But keep in mind that querying a stream is similar to querying a table. If a stream has a large number of changes that have not been consumed, querying the stream could take longer.
Impact on DML Operations
DML operations on a table with a stream may experience a slight increase in latency. This is because every DML operation on the table needs to record the changes to the metadata for the stream.
In general, the impact is minimal and likely unnoticeable in most use cases. But for workloads with a high rate of DML operations, the impact could be more significant.
Data Retention and Storage Costs
Streams rely on Snowflake’s Time Travel feature, which retains historical data for a specified period.
This means that the data changed in the table is stored twice:
- once in the table itself
- once in the Time Travel history
This could increase storage costs. Consider adjusting the Time Travel data retention period to balance the need for accessing historical data with storage costs.
Stream Staleness
Be aware of the risk of streams becoming stale. A stale stream cannot capture new changes to the table.
To maintain the performance of your ETL processes, monitor the status of your streams and recreate them if necessary.