Are you just getting started with Databricks? Getting confused about the difference between workspaces, notebooks, and clusters?
This article tells you all you need to know about the important concept of a workspace on the Databricks platform.
Table of Contents
What Is A Databricks Workspace?
A Databricks workspace is a shared environment where you can collaborate with others on various tasks related to data engineering, data science, machine learning, and more.
Think of an office workspace with areas where you keep all your reports, documents, and tools for work. A Databricks workspace is similar but in a digital format.
It has areas for your notebooks, libraries, experiments, and jobs. Each user can view, create, edit, or run these components within the workspace, subject to their permissions.
What Does A Databricks Workspace Look Like?
When you log into Databricks, you land into the Workspace user interface. The left sidebar is your is your starting point for all tasks.
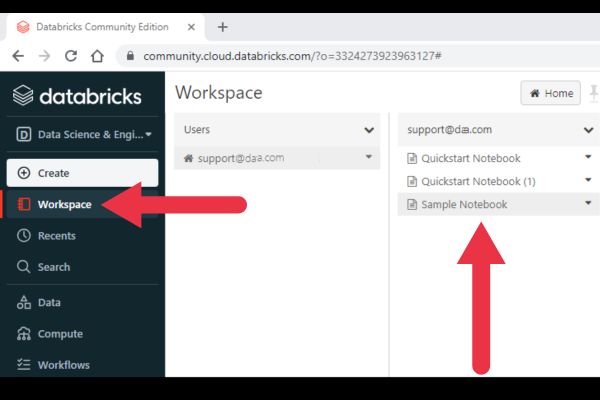
Here is a rundown of the left sidebar:
- Workspace: shows your notebooks, libraries, and other assets.
- Recent: shows recently used or viewed notebooks and other resources.
- Data: an interface to databases and tables.
- Compute: an interface to create, view, and manage clusters.
- Worfklows: create and schedule jobs, and monitor their execution.
What Is Inside A Workspace?
There are several types of assets that a workspace can hold. As a beginner, you’ll quickly learn how to use the first two types on this list (notebooks, jobs, and clusters). It may be a while before you get to the rest of these assets.
- Notebooks
- Jobs
- Clusters
- Libraries
- Repos
- Models
Notebooks are the workhorses of Databricks. This is where users write and execute code, analyze data, and document their findings. You can learn more in our introduction to Databricks Notebooks.
The workspace also provides a user-friendly dashboard to manage jobs. These are tasks or series of tasks executed on clusters. If you’re not sure about how this works, check out our introduction to Databricks clusters.
The workspace organizes and manages libraries. These are packages or modules that provide additional functionality. For example, you could use a machine-learning Python library like scikit. Libraries can be added to clusters and used within notebooks.
Repos are repositories for source control that are integrated with Git. Depending on your environment, you may not use them.
A Model in the Databricks workspace generally refers to a machine learning model that has been trained and logged to the Model Registry using MLflow. This is very specific – if you’re not involved with machine learning, you won’t encounter these in your workspace.
Workspace Roles And Permissions

A role in Databricks is a collection of permissions. The permissions define what actions a user with that role can perform.
The permissions of a role are scoped to workspace objects. This means that a role’s permissions can be applied to individual notebooks, jobs, and other objects within the workspace.
For example, a user might have permission to edit one notebook but only view another.
Workspace Vs Clusters
Workspaces and clusters play key roles in a Databricks set-up, but they are fundamentally different and serve unique purposes.
A workspace is the shared environment where users carry out their tasks using assets like notebooks, libraries, jobs, and data.
Clusters are sets of computational resources where the actual data processing occurs. In Databricks, a cluster is a distributed computing system made up of a driver node and worker nodes that process your data and execute your commands.
The essential difference is that the workspace is where users write code, but the cluster is where that code gets executed.
What Is The Data Science & Engineering Workspace
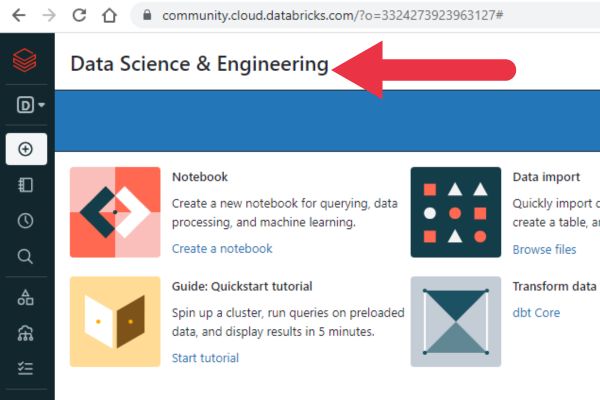
If you’re trying the Databricks Community Edition, the first place you’ll land when you log in is the Data Science & Engineering Workspace. So, what is it?
This workspace is a collaborative platform specifically designed for data scientists and data engineers to work together.
These notebooks support multiple languages (Python, SQL, R, Scala), allowing data scientists and engineers to use the language they are most comfortable with.
How To Get the Workspace ID
To find your Workspace ID, log into your Databricks account and go to the workspace (if you have several).
Look at the URL displayed in your browser address area. I’ve highlighted mine in the picture below.
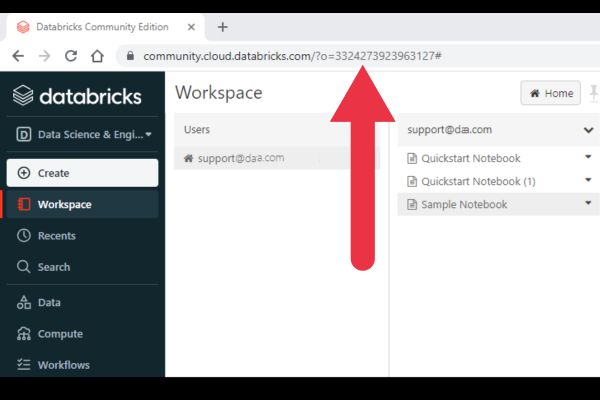
The ID is a series of a numbers displayed after the text “o=”.
If there is no o= in the URL, the ID is 0.
How To Find Your Workspace Name
In Databricks, your workspace name typically corresponds to the workspace URL that appears before the numeric ID.
To find the name visually, look at the URL in your browser’s address bar. As long as you’re not using the Community Edition, the URL will be something like:
https://<workspace-name>.cloud.databricks.com
The <workspace-name> part of the URL is typically the name of your workspace.
You can also capture this name programmatically in a Python Notebook. Here is one way to do so:
spark.conf.get("spark.databricks.workspaceUrl").split('.')[0]Quick History Of The Databricks Workspace
Databricks was launched as a company in 2013 when they raised $14 million in Series A funding.
The company launched their cloud platform in the summer of 2014. The marketing spiel described the Databricks Workspace as an interface that provided:
three powerful web-based applications: notebooks, dashboards, and a job launcher .
Databricks blog
You may have noticed that some assets I mentioned early are missing from that list. That’s because the original Workspace was quite limited in what it offered. This hampered widespread adoption of the platform.
Things changed drastically in 2020 when the Workspace features expanded to include libraries, repos, and models.