Did you know that we can trace the origins of Apache Spark back to Google’s published research on distributed processing? But Google didn’t create Spark.
This article looks at what came before Spark, how and where the innovative technology was created, and the key individuals involved in its inception.
Let’s start at the beginning and trace the spark (pun intended) that ignited the big data revolution.
Google’s MapReduce: Where It All Began
In the early 2000s, Google’s search engine was struggling to deal with indexing an exponentially growing amount of data on the web.
The company needed a more efficient way to process the vast amount of data. Google had several research teams working on a problem that threatened its future.
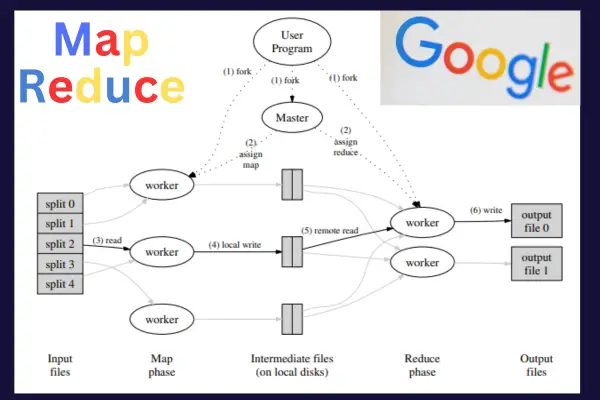
In 2004, Google engineers Jeffrey Dean and Sanjay Ghemawat released a seminal paper titled “MapReduce: Simplified Data Processing on Large Clusters”. This described a new framework for indexing.
The framework introduced a programming model with two stages: Map and Reduce.
Map and Reduce
The Map stage divided the problem into numerous small sub-problems (the Map stage). These sub-problems could be processed independently across many different machines in a distributed system.
The next stage would take the results from the many different machines. The data would be aggregated, sorted, and further processed. This is the Reduce stage.
Distributed computing wasn’t a new concept here. But the goal of MapReduce was to manage two significant challenges:
- High complexity
- Multiple machines and components for failure
Simplifying Complexity
The programming model for processing large amounts of data across many machines is necessarily complex. But the MapReduce model hid that complexity from developers who could focus on the “map” and “reduce” functions.
The underlying framework would handle the complexities of data distribution, redundancy, and fault tolerance.
Improving Reliability
A large distributed system is based on clusters of commodity hardware. There are many different parts and components that can fail and potentially bring down the entire system.
The MapReduce framework included many built-in features to manage hardware or network failures.
Two Consequences Of MapReduce
It’s fair to say that for Google, the main consequence of MapReduce was to make the search engine the behemoth it is today.
The new approach allowed Google to process enormous amounts of data more efficiently. It was a major contributor to their ability to index the rapidly expanding internet.
The second consequence was to the wider tech community. Google’s MapReduce inspired other open-source distributed computing projects. That includes Apache Hadoop, that brought similar capabilities to the broader technology world.
Origins Of Hadoop MapReduce
The story of Hadoop starts with Doug Cutting and Mike Cafarella in the early 2000s.
Cutting was working at Xerox’s PARC (Palo Alto Research Center) in 2002, while Cafarell was a graduate student at the University of Washington.
The pair collaborated on an independent project to develop an open-source web-search engine that could compete with commercial versions (i.e. Google, Yahoo, and others of that time).
This was known as the “Nutch” project. Their main stumbling block was handling large-scale data processing.
Google published a paper on distributed file systems (Google File System or GFS) in 2003. A year later, they published their MapReduce paper.
Doug Cutting realized that these technologies could solve their challenges with Nutch. He started working on an open-source implementation that included:
- a distributed file system (this became the Hadoop Distributed File System, or HDFS)
- a programming model that became MapReduce.
Cutting named this new implementation “Hadoop”.
Why? This was the name of a toy elephant that belonged to his son. Cute, eh? And here’s the logo to go with the whimsy…

Enter Yahoo
Yahoo hired Doug Cutting in 2006. At the time, the company was a giant in the field of internet search. They allowed Cutting to devote his time to developing Hadoop.
It’s fair to say that Yahoo was a significant player in pushing Hadoop toward where it became. The commercial company gave Cutting and a small development team the space to let the open-source framework mature.
Ironically, younger readers may be wondering…Yahoo?..Who?
The first usable version of Hadoop was released in 2008.
Consequences
Over time, Hadoop became the foundation for the big data ecosystem. Other systems, such as Apache Hive and Apache HBase, were built on top of the framework.
Its ability to process large volumes of data across clusters of computers fundamentally changed the way companies and organizations could work with big data.
Origins Of Apache Spark
A year after the Hadoop release of 2008, a research student named Matei Zaharia was starting his Ph.D. project at Berkeley’s AMPLab at the University of California. AMPLab stands for the Algorithms, Machines, and People Lab.
Zaharia wanted to fix two major issues with Hadoop. The first was the speed limitations with massive data due to Hadoop being disk-based (i.e. frequently writing to physical hardware).
The second was that the framework was focused on batch processing and Zaharia wanted to extend the capabilities for interactive queries and streaming.
He started collaborating with other distributed computing PhD students on a class project that they called the Mesos platform. Zaharia wrote a machine learning engine to run on top of the platform. He called it Spark.
Meanwhile, a machine learning PhD student called Lester Mackey hit Zaharia up for some help. Mackey was a member of a student team trying to win a programming competition sponsored by Netflix.
The goal was to build a recommendation engine. But Mackey was concerned that his team’s models were running too slow on Hadoop.

Zaharia helped him get set up on Spark which drove their competition entry to second place.
The following year, Zaharia open-sourced the early software under a BSD license. This is the Berkeley Software Distribution that allows other developers to freely use, modify, and distribute the software.
An increasing number of Berkeley students and professors were excited by the capabilities of this new project and contributed to the development of Spark.
Enter Apache
The Apache Software Foundation (ASF) is a non-profit corporation established in 1999. Its mission is to provide software for the public good.
Each Apache project is managed by a self-selected team of technical experts who are active contributors to the project.
The Berkeley team switched the licensing to the Apache Software Foundation in 2013. It was so popular with the developer community that it became a Top-Level project the following year.

Early Key Contributors To Spark
There were many more contributors to the early Spark versions than I can mention here, but I’ll give a few.
Michael Franklin wasn’t a developer per se, but as the Director of the AMPLab, he played a crucial leadership role in steering the project.
Mosharaf Chowdhury was a Ph.D. student at the time who contributed several features to the code base. He has continued in the academic world and became professor of computer science at the University of Michigan.
Tathagata Das also contributed to early streaming aspects for real-time data processing.
I’ve already mentioned Ion Stoica. As a professor and Matei Zaharia’s Ph.D. supervisor, he also co-authored academic papers underlying the framework.
Of course, Matei Zaharia was the catalyst for the Spark project. He went on to co-found Databricks with some other key contributors.
Reynold Xin was a lead developer and one of the earliest committers of code on the project. Andy Konwinski and Patrick Wendell were other early contributors.
Several of these individuals became co-founders of Databricks (another interesting story!).